ClerkCore
Clerk.io tager din butiks produktkatalog og ordredata, kører det gennem en prædiktiv AI-motor, og gør resultaterne tilgængelige via et API, der driver Search, Recommendations, Email og Audience.
Denne artikel forklarer, hvad der sker bag kulisserne — nyttig baggrund for alle, der opsætter en integration, fejlsøger uventede resultater eller blot er nysgerrig på, hvor intelligensen stammer fra.
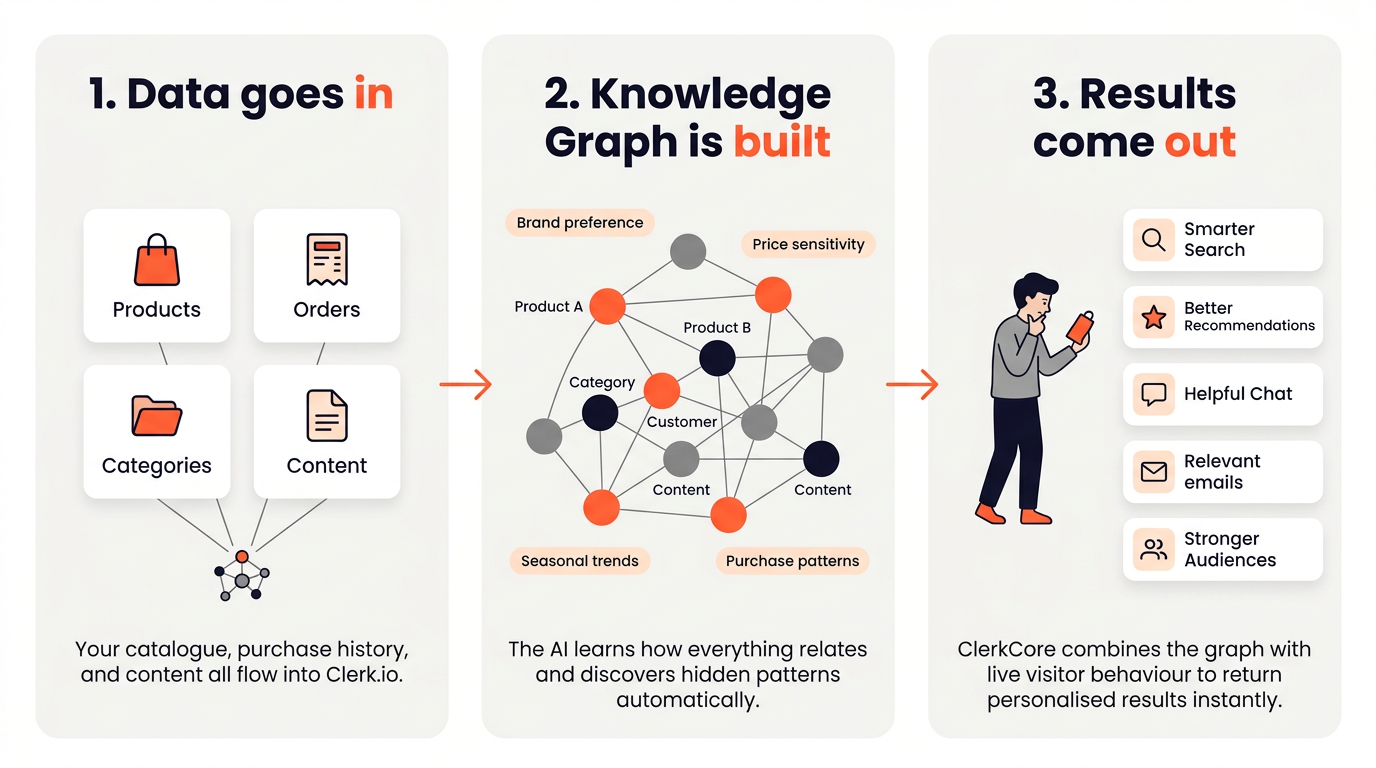
Alt hvad Clerk.io gør, kan opsummeres i tre trin:
- Sync — dit produktkatalog og din ordredata importeres til Clerk.io.
- Analyse — ClerkCore, Clerk.io’s AI-motor, behandler data og forbereder kundeintensitetsmodeller.
- Serve — Prediction API besvarer forespørgsler i realtid ved at kombinere forudberegnede indsigter med live besøgsadfærd.
Når en besøgende ser på et produkt, bliver API’en spurgt noget lignende: “Denne besøgende kigger på produkt X — hvad vil de sandsynligvis købe næste gang?” ClerkCore har allerede svaret forudberegnet, så responsen er næsten øjeblikkelig.
The Knowledge Graph #
Kernen i ClerkCore er en teknologi kaldet Knowledge Graph — et sammenkoblet netværk, der forbinder hvert produkt, kategori, kunde og indholdsstykke i din butik.
Hver forbindelse i grafen har to egenskaber: længde og styrke. Jo kortere forbindelsen mellem to ting, desto tættere er de relateret. Jo stærkere forbindelsen er, desto mere selvsikker er AI omkring den relation.
Ud over eksplicitte datapunkter som produkter og kategorier opbygger Knowledge Graph også noget, man kan kalde virtuelle noter — abstrakte mønstre, der indfanger ting som brand-præference, prissensitivitet og sæsonbestemte trends. Dette er ikke felter, du sender til Clerk.io; de opstår automatisk ud fra mønstrene i dine ordrer og browserdata.
Når en besøgende lander på en produktside, gennemgår ClerkCore grafen i realtid for at finde de nærmeste naboer — de produkter, kategorier og det indhold, der er mest relevant for den specifikke besøgende på det specifikke tidspunkt — og kombinerer flere adfærdsmodeller for at skabe et personligt resultat.
Three Subsystems #
Clerk.io er bygget op omkring tre delsystemer, som alle arbejder omkring en central Data Store.
Data Sync #
Data Sync-infrastrukturen holder Clerk.io’s Data Store opdateret med dit katalog og dine ordrer til enhver tid.
Det fungerer i to lag. En platformspecifik importør læser data fra din webshop i dets oprindelige format og sender dem videre til en Core Importer, som validerer og gemmer dataene i et ensartet internt format. Det gør at Clerk.io kan understøtte mange forskellige platforme uden at kræve, at hver enkelt passer til et stramt dataschema.
Synkronisering kører efter en tidsplan — Clerk.io justerer hyppigheden baseret på, hvor hurtigt dit katalog ændres, og hvor lang tid synkroniseringen tager at gennemføre. Du kan også starte en synkronisering manuelt eller skubbe individuelle opdateringer i realtid via CRUD API.
Hvis du oplever et pludseligt fald i resultatkvalitet, er forkerte data i sync den mest almindelige årsag. Data Health dashboardet er det første sted at tjekke.
ClerkCore #
ClerkCore er Clerk.io’s AI-motor. Den analyserer periodisk data i Data Store og forudberegner kundeintensitetsmodeller — lærer hvilke produkter, der ofte købes sammen, hvad kunder med lignende historik sandsynligvis vil gøre næste gang, og hvordan de overordnede købsmønstre ser ud i kataloget.
Hvert kunde-adfærdsmønster bliver til sin egen model. ClerkCore bygger mange modeller parallelt og kombinerer dem dynamisk i forespørgselsøjeblikket, baseret på hvad den enkelte besøgende gør lige nu.
I modsætning til ældre tilgange som collaborative filtering eller neurale netværk har ClerkCore ikke et cold-start problem for nye produkter. Et helt nyt produkt kan optræde i resultaterne så snart det er synkroniseret, fordi grafen bruger dets kategori, pris og attributter til at placere det i kontekst — selv før det har nogen egen ordredata.
Resultater tilpasser sig også automatisk til trends og sæsoner, da grafen løbende omvægter forbindelser baseret på nylig adfærd i stedet for at bygge på statiske træningskørsler.
Disse modeller opdateres automatisk, når der sker væsentlige ændringer i dataene. Når en butik først udfyldes, kan den indledende analyse tage et par minutter, før resultaterne vises via API’et. Derefter sker opdateringer løbende i baggrunden.
Prediction API #
Prediction API på api.clerk.io er grundlaget for resten af Clerk.io. Når en besøgende udløser et søg eller loader en recommendations-slider, kombinerer API’et ClerkCore’s forudberegnede modeller med besøgendes realtidsadfærd for at returnere en rangeret liste af produkter.
Nogle eksempler på forespørgsler, som API’en besvarer:
- “Denne besøgende ser på produkt Y — hvad er gode alternativer?” →
recommendations/substituting - “Denne besøgende har netop tilføjet produkt Y til kurven — hvad vil de sandsynligvis købe sammen med det?” →
recommendations/complementary - “Hvilke kunder er mest tilbøjelige til at være interesseret i produkt X?” → bruges af Audience
Search, Recommendations, Email og Audience er alle bygget som lag ovenpå disse kerne-API-funktioner.
Required Input Data #
ClerkCore kræver to ting for at skabe resultater:
- Products — det aktuelle katalog, med minimum id, navn, pris, billede, url, kategorier og created_at.
- Orders — købsdata, med minimum id, produkter og tidspunkt.
Alt andet — kategorier, kunder og sider — er teknisk set valgfrit, men at sende det forbedrer markant resultatkvaliteten. Kategorier hjælper AI’en med at forstå din katalogstruktur, kunder muliggør Audience-segmentering baseret på kundeattributter, og sider muliggør indholds-anbefalinger og mere rige søgeresultater. Vi anbefaler stærkt at sende det hele.
Jo mere ordredata, der er til rådighed, desto bedre bliver forudsigelserne. En butik, der har kørt i årevis med tusindvis af ordrer, vil opleve væsentlig stærkere resultater end en, der netop er gået live. Når det er sagt, begynder Clerk.io at levere brugbare resultater, så snart der findes nok ordrer til at identificere mønstre — typisk er et par hundrede ordrer nok til at komme i gang.
For flere oplysninger om dataobjekter og deres påkrævede felter, se Data Foundation.
Denne side er oversat af en hjælpsom AI, og der kan derfor være sproglige fejl. Tak for forståelsen.