ClerkCore
Clerk.io nimmt den Produktkatalog und die Bestellhistorie Ihres Shops, führt sie durch eine prädiktive KI-Engine und stellt die Ergebnisse über eine API zur Verfügung, die Search, Recommendations, Email und Audience antreibt.
Dieser Artikel erklärt, was im Hintergrund passiert — ein nützlicher Kontext für alle, die eine Integration einrichten, unerwartete Ergebnisse debuggen oder einfach neugierig sind, woher die Intelligenz stammt.
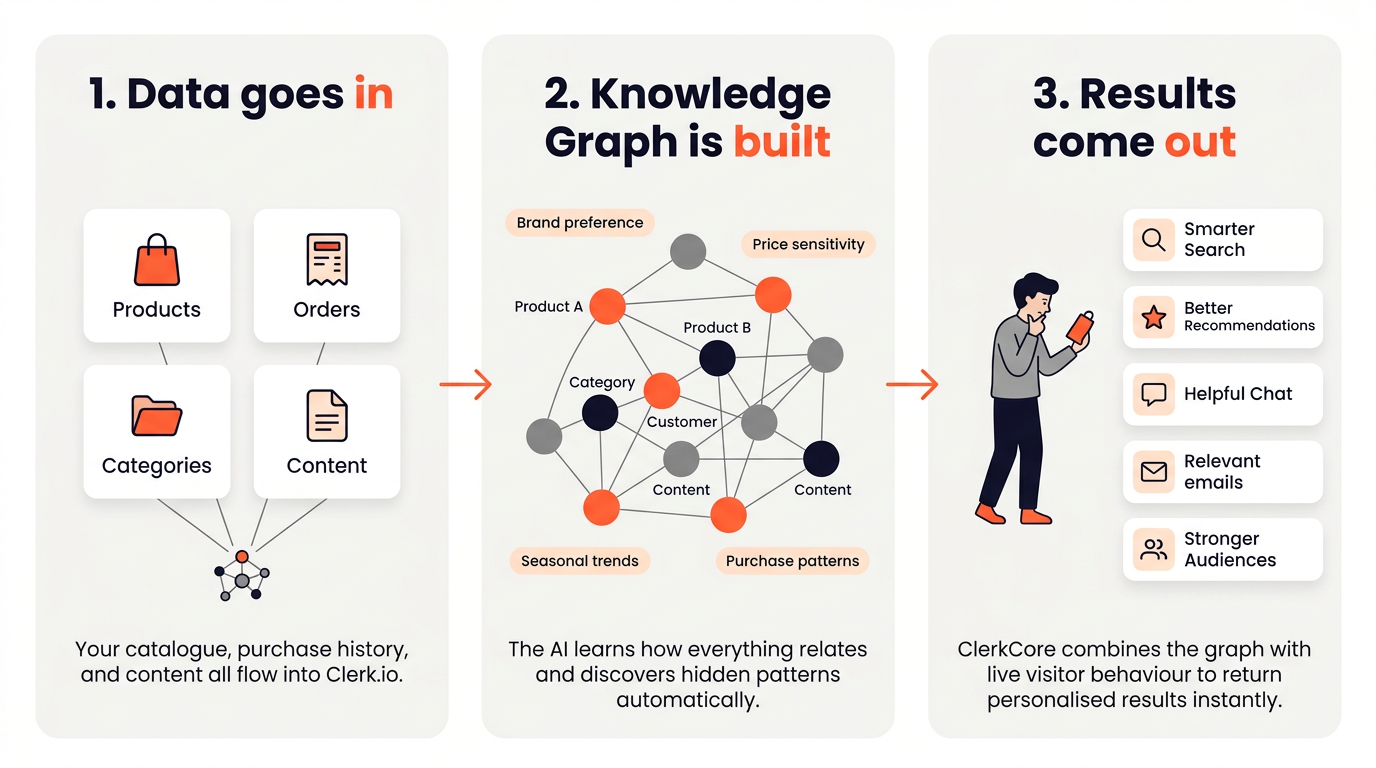
Alles, was Clerk.io tut, läuft auf drei Schritte hinaus:
- Sync — Ihr Produktkatalog und Ihre Bestellhistorie werden in Clerk.io importiert.
- Analyse — ClerkCore, Clerk.ios KI-Engine, verarbeitet die Daten und berechnet Kundenintenzionsmodelle vor.
- Serve — die Prediction API beantwortet Echtzeitanfragen, indem sie vorab berechnete Erkenntnisse mit dem aktuellen Besucherverhalten kombiniert.
Wenn ein Besucher ein Produkt ansieht, wird die API mit einer Frage wie dieser angefragt: “Dieser Besucher schaut sich Produkt X an — was wird er als Nächstes am ehesten kaufen?” ClerkCore hat die Antwort bereits vorab berechnet, sodass die Antwort nahezu sofort erfolgt.
The Knowledge Graph #
Das Herzstück von ClerkCore ist eine Technologie namens Knowledge Graph — ein miteinander verbundenes Netzwerk, das jedes Produkt, jede Kategorie, jeden Kunden und jeden Inhalt in Ihrem Shop verknüpft.
Jede Verbindung im Graphen hat zwei Eigenschaften: Länge und Stärke. Je kürzer die Verbindung zwischen zwei Elementen, desto enger sind sie miteinander verwandt. Je stärker die Verbindung, desto sicherer ist die KI über diese Beziehung.
Zusätzlich zu expliziten Datenpunkten wie Produkten und Kategorien erstellt der Knowledge Graph auch sogenannte virtuelle Notizen — abstrakte Muster, die Dinge wie Markenaffinität, Preissensibilität und saisonale Trends erfassen. Diese sind keine Felder, die Sie an Clerk.io senden; sie entstehen automatisch aus den Mustern in Ihren Bestell- und Browsedaten.
Wenn ein Besucher auf einer Produktseite landet, durchläuft ClerkCore den Graphen in Echtzeit, um die nächsten Nachbarn zu finden — also die Produkte, Kategorien und Inhalte, die für diesen spezifischen Besucher in diesem spezifischen Moment am relevantesten sind — und kombiniert verschiedene Verhaltensmodelle, um ein personalisiertes Ergebnis zu liefern.
Three Subsystems #
Clerk.io basiert auf drei Subsystemen, die alle um einen zentralen Data Store arbeiten.
Data Sync #
Die Data Sync Infrastructure hält Clerk.ios Data Store stets mit Ihrem Katalog und den Bestellungen auf dem aktuellen Stand.
Sie funktioniert in zwei Schichten. Ein plattformspezifischer Importer liest Daten aus Ihrem Webshop in dessen nativen Format und übergibt sie an einen Core Importer, der sie validiert und in einem konsistenten internen Format speichert. Dadurch kann Clerk.io viele verschiedene Plattformen unterstützen, ohne dass jede einer starren Datenstruktur entsprechen muss.
Synchronisierungen laufen nach Zeitplan — Clerk.io passt die Häufigkeit an, je nachdem wie schnell sich Ihr Katalog ändert und wie lang die Synchronisierung dauert. Sie können eine Synchronisierung auch manuell starten oder einzelne Aktualisierungen in Echtzeit über die CRUD API senden.
Wenn Sie einen plötzlichen Qualitätsabfall der Ergebnisse feststellen, ist fehlerhafte Daten beim Sync die häufigste Ursache. Das Data Health Dashboard ist der erste Ort zur Überprüfung.
ClerkCore #
ClerkCore ist Clerk.ios KI-Engine. Sie analysiert regelmäßig die im Store befindlichen Daten und berechnet Kundenintensionsmodelle vor — sie lernt, welche Produkte gemeinsam gekauft werden, was Kunden mit ähnlicher Historie tendenziell als nächstes tun und wie die allgemeinen Kaufmuster im Katalog aussehen.
Jedes Kundenverhaltensmuster wird zu einem eigenen Modell. ClerkCore baut viele Modelle parallel auf und kombiniert sie dynamisch zur Anfragezeit, basierend darauf, was der einzelne Besucher gerade tut.
Anders als ältere Ansätze wie kollaboratives Filtern oder neuronale Netze hat ClerkCore kein Cold-Start-Problem bei neuen Produkten. Ein komplett neues Produkt kann in den Ergebnissen erscheinen, sobald es synchronisiert ist, denn der Graph nutzt dessen Kategorie, Preis und Attribute, um es in den Kontext einzuordnen — noch bevor das Produkt eine eigene Verkaufshistorie hat.
Die Ergebnisse passen sich auch automatisch an Trends und Saisons an, da der Graph die Verbindungen kontinuierlich anhand aktuellen Verhaltens neu gewichtet und nicht auf statische Trainingsläufe angewiesen ist.
Diese Modelle werden automatisch aktualisiert, wann immer sich bedeutsame Änderungen in den Daten ergeben. Wird ein Store erstmals mit Daten befüllt, kann die erste Analyse einige Minuten dauern, bevor Ergebnisse über die API sichtbar sind. Danach laufen die Aktualisierungen kontinuierlich im Hintergrund.
Prediction API #
Die Prediction API unter api.clerk.io bildet die Grundlage für alles Weitere bei Clerk.io. Wenn ein Besucher eine Suche auslöst oder einen Recommendations-Slider lädt, kombiniert die API ClerkCores vorab berechnete Modelle mit dem Echtzeit-Sitzungsverhalten des Besuchers, um eine gerankte Liste von Produkten zu liefern.
Einige Beispielanfragen, die die API beantwortet:
- “Dieser Besucher sieht sich Produkt Y an — was sind gute Alternativen?” →
recommendations/substituting - “Dieser Besucher hat gerade Produkt Y zum Warenkorb hinzugefügt — was kauft er wahrscheinlich noch dazu?” →
recommendations/complementary - “Welche Kunden sind am wahrscheinlichsten an Produkt X interessiert?” → verwendet von Audience
Search, Recommendations, Email und Audience sind alle als Schichten auf diesen Kern-API-Funktionen aufgebaut.
Required Input Data #
ClerkCore benötigt zwei Dinge, um Ergebnisse zu liefern:
- Produkte — der aktuelle Katalog, mindestens mit id, name, price, image, url, categories, und created_at.
- Orders — Kaufhistorie, mindestens mit id, products und time.
Alles andere — Kategorien, Kunden und Seiten — ist technisch optional, verbessert die Ergebnisqualität jedoch erheblich. Kategorien helfen der KI, Ihre Katalogstruktur zu verstehen, Kunden ermöglichen Audience-Segmentierung nach Kundenattributen und Seiten öffnen Content-Empfehlungen und reichhaltigere Suchergebnisse. Wir empfehlen dringend, alles zu übermitteln.
Je mehr Bestellhistorie vorhanden ist, desto besser werden die Vorhersagen. Ein Shop, der seit Jahren mit Tausenden Bestellungen läuft, erzielt deutlich stärkere Ergebnisse als einer, der gerade erst online gegangen ist. Gleichwohl produziert Clerk.io sofort sinnvolle Resultate, sobald genügend Bestellungen vorhanden sind, um Muster zu erkennen — typischerweise reichen schon einige Hundert, um zu starten.
Weitere Informationen zu Datenobjekten und deren erforderlichen Feldern finden Sie unter Data Foundation.
Diese Seite wurde von einer hilfreichen KI übersetzt, daher kann es zu Sprachfehlern kommen. Vielen Dank für Ihr Verständnis.