ClerkCore
Clerk.io toma el catálogo de productos y el historial de pedidos de tu tienda, lo procesa a través de un motor de IA predictiva y pone los resultados a disposición mediante una API que impulsa Search, Recommendations, Email y Audience.
Este artículo explica lo que sucede tras bambalinas — contexto útil para cualquier persona que esté configurando una integración, depurando resultados inesperados o simplemente tenga curiosidad sobre de dónde proviene la inteligencia.
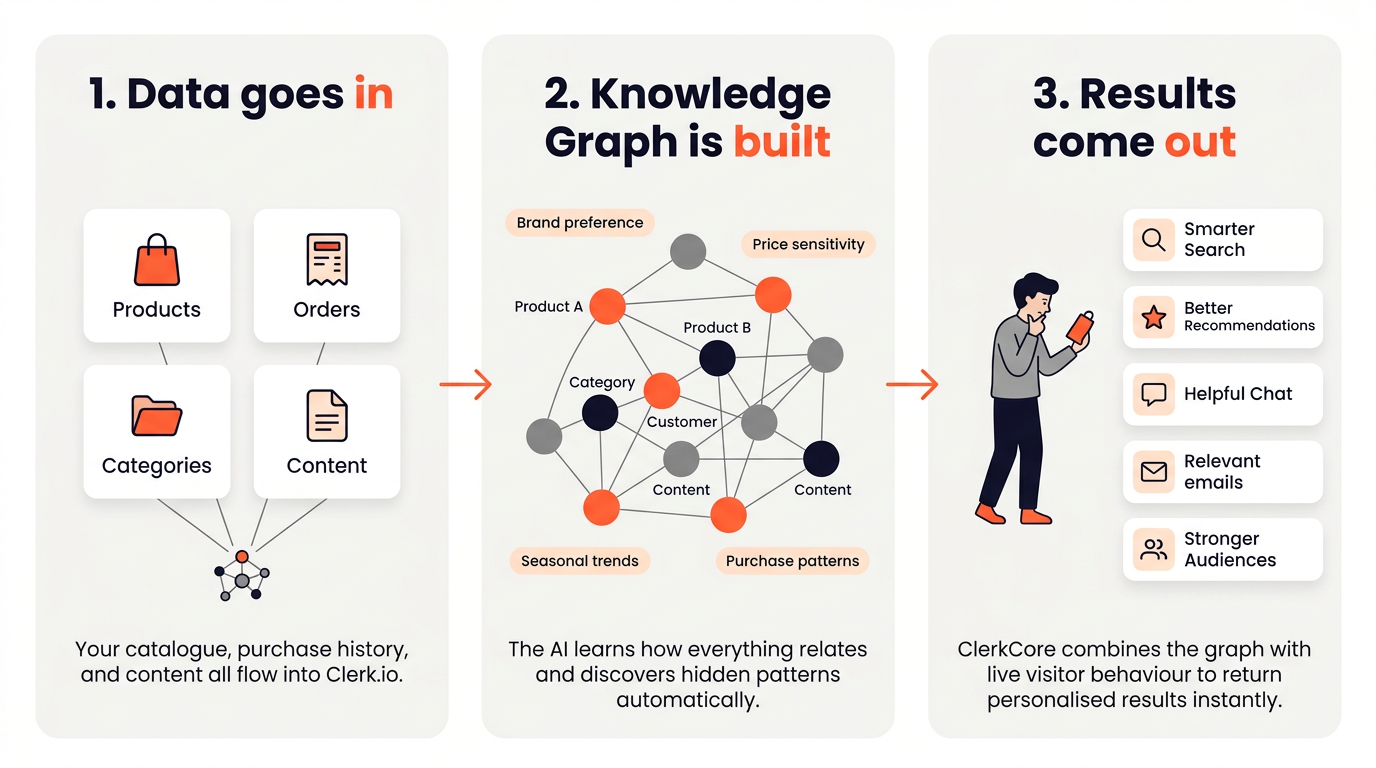
Todo lo que hace Clerk.io se resume en tres pasos:
- Sincronizar — tu catálogo de productos e historial de pedidos se importan en Clerk.io.
- Analizar — ClerkCore, el motor de IA de Clerk.io, procesa los datos y precomputa modelos de intención del cliente.
- Servir — la Prediction API responde consultas en tiempo real combinando información precomputada con el comportamiento en vivo del visitante.
Cuando un visitante visualiza un producto, la API recibe una consulta como: “Este visitante está viendo el producto X — ¿qué es lo que probablemente comprará después?” ClerkCore ya tiene la respuesta precomputada, por lo que la respuesta es casi instantánea.
El Knowledge Graph #
El núcleo de ClerkCore es una tecnología llamada Knowledge Graph — una red interconectada que enlaza cada producto, categoría, cliente y pieza de contenido en tu tienda.
Cada conexión del grafo tiene dos propiedades: longitud y fuerza. Cuanto más corta es la conexión entre dos elementos, más estrechamente relacionados están. Cuanto más fuerte es la conexión, mayor confianza tiene la IA en esa relación.
Además de los datos explícitos como productos y categorías, el Knowledge Graph también genera lo que podrías llamar notas virtuales — patrones abstractos que capturan afinidad de marca, sensibilidad al precio y tendencias estacionales. Estos no son campos que envías a Clerk.io; surgen automáticamente a partir de los patrones en tus datos de pedidos y navegación.
Cuando un visitante llega a una página de producto, ClerkCore recorre el grafo en tiempo real para encontrar los vecinos más cercanos — los productos, categorías y contenido más relevantes para ese visitante específico en ese momento específico — y combina múltiples modelos de comportamiento para producir un resultado personalizado.
Tres Subsistemas #
Clerk.io se construye alrededor de tres subsistemas que operan en torno a un Data Store central.
Sincronización de Datos #
La Infraestructura de Sincronización de Datos mantiene el Data Store de Clerk.io actualizado con tu catálogo y pedidos en todo momento.
Funciona en dos capas. Un importador específico de la plataforma lee los datos de tu e-commerce en su formato nativo y los pasa a un Core Importer, que los valida y almacena en un formato interno consistente. Esto permite que Clerk.io sea compatible con muchas plataformas diferentes sin requerir que cada una se adapte a un esquema de datos rígido.
Las sincronizaciones se ejecutan en un horario — Clerk.io ajusta la frecuencia según la rapidez con la que cambia tu catálogo y cuánto tiempo tarda en completarse la sincronización. También puedes iniciar una sincronización manualmente o enviar actualizaciones individuales en tiempo real a través del CRUD API.
Si observas una caída repentina en la calidad de los resultados, los datos incorrectos en la sincronización son la causa más común. El panel de Data Health es el primer lugar donde debes revisar.
ClerkCore #
ClerkCore es el motor de IA de Clerk.io. Analiza periódicamente los datos en el store y precomputa modelos de intención del cliente — aprendiendo qué productos se compran juntos, qué tienden a hacer los clientes con historiales similares, y cómo se ven en general los patrones de compra en el catálogo.
Cada patrón de comportamiento del cliente se convierte en su propio modelo. ClerkCore construye muchos modelos en paralelo y los combina dinámicamente en el momento de la consulta basándose en lo que está haciendo el visitante en ese instante.
A diferencia de enfoques antiguos como el filtrado colaborativo o redes neuronales, ClerkCore no tiene problema de cold-start con productos nuevos. Un producto completamente nuevo puede aparecer en los resultados tan pronto como se sincroniza, porque el grafo utiliza su categoría, precio y atributos para ubicarlo en contexto — incluso antes de que tenga historial de pedidos propio.
Los resultados también se adaptan automáticamente a tendencias y temporadas, ya que el grafo reevalúa continuamente las conexiones basándose en comportamientos recientes en lugar de depender de entrenamientos estáticos.
Estos modelos se actualizan automáticamente cada vez que ocurren cambios significativos en los datos. Cuando la tienda se popula por primera vez, el análisis inicial puede tardar algunos minutos antes de que aparezcan los resultados mediante la API. Luego, las actualizaciones suceden de manera continua en segundo plano.
Prediction API #
La Prediction API en api.clerk.io es la base sobre la que se construye el resto de Clerk.io. Cuando un visitante realiza una búsqueda o carga un slider de recomendaciones, la API combina los modelos precomputados de ClerkCore con el comportamiento en tiempo real de la sesión para devolver una lista clasificada de productos.
Algunos ejemplos de consultas que responde la API:
- “Este visitante está viendo el producto Y — ¿cuáles son buenas alternativas?” →
recommendations/substituting - “Este visitante acaba de añadir el producto Y al carrito — ¿qué probablemente comprará junto a él?” →
recommendations/complementary - "¿Qué clientes tienen más probabilidades de estar interesados en el producto X?" → utilizado por Audience
Search, Recommendations, Email y Audience están construidos como capas sobre estas capacidades principales de la API.
Datos de Entrada Requeridos #
ClerkCore necesita dos cosas para producir resultados:
- Productos — el catálogo actual, con al menos id, nombre, precio, imagen, url, categorías y created_at.
- Pedidos — historial de compras, con al menos id, productos y tiempo.
Todo lo demás — categorías, clientes y páginas — es técnicamente opcional, pero mejora significativamente la calidad de los resultados al enviarlo. Las categorías ayudan a la IA a entender la estructura de tu catálogo, los clientes habilitan la segmentación de Audience basada en atributos de cliente, y las páginas permiten recomendaciones de contenido y resultados de búsqueda más ricos. Recomendamos encarecidamente enviar todo.
Cuanto más historial de pedidos haya disponible, mejores serán las predicciones. Una tienda que opera desde hace años con miles de pedidos verá resultados notablemente más sólidos que una que acaba de activarse. Dicho esto, Clerk.io comienza a generar resultados útiles tan pronto como hay suficientes pedidos para identificar patrones — normalmente unos pocos cientos de pedidos son suficientes para empezar.
Para más información sobre los objetos de datos y sus campos obligatorios, consulta Data Foundation.
Esta página ha sido traducida por una IA útil, por lo que puede contener errores de idioma. Muchas gracias por su comprensión.